🤠 Add Hifigan vocoder #387
Conversation
|
@machineko @ZDisket can you guys try to training around 2k steps to verify if it works :))) I do not have GPU right now to test :))). There are so many differences between a private library and this opensource:v. |
Same not available GPU at the moment but will test in 2/3 days 📦 |
|
@dathudeptrai Did u wanna to use config v2 or v1 for it? |
I could train 4k steps and counting with v1 config and mixed precision without problems. I even got eval samples at 5k. |
v2 for faster :D |
is the loss ok ? , can you try to continue training both G and D around 1k steps :D |
|
@dathudeptrai For some reason the loss exploded after 10k and the eval samples are either noise or silence, although I think it's just because of the small dataset. Going to restart training and train discriminator from 0 steps |
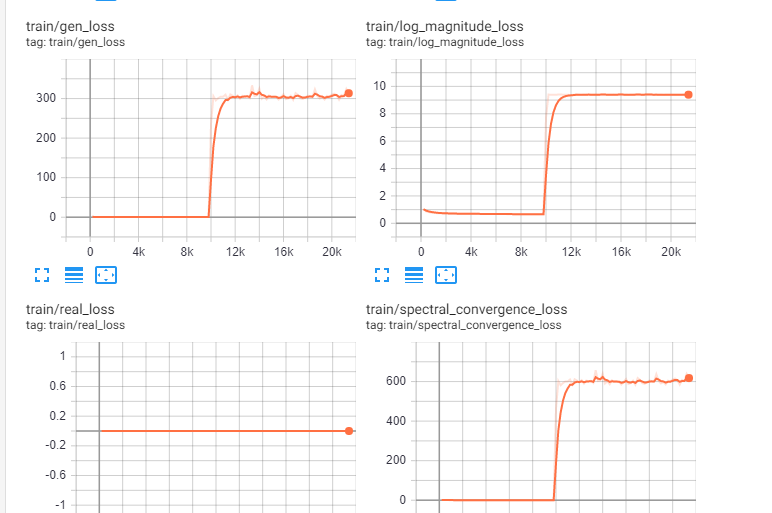
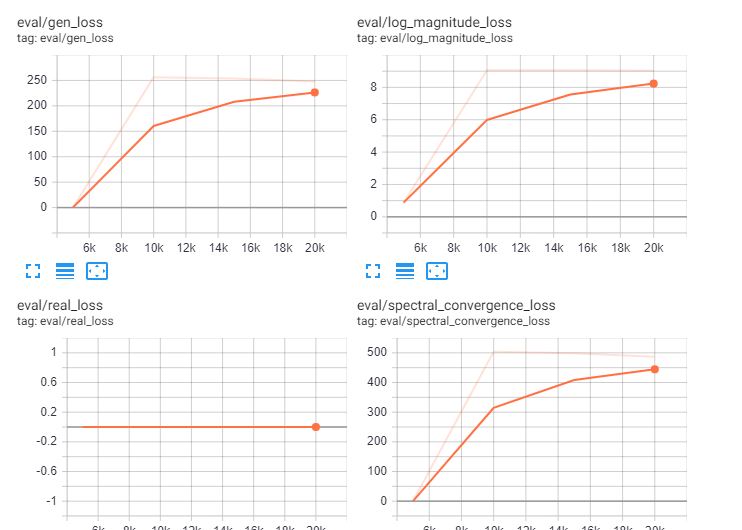
Completed 2k steps of G+D starting from 0 steps. No problems. |
|
@ZDisket could you share your hifigan tensorboard like this? |
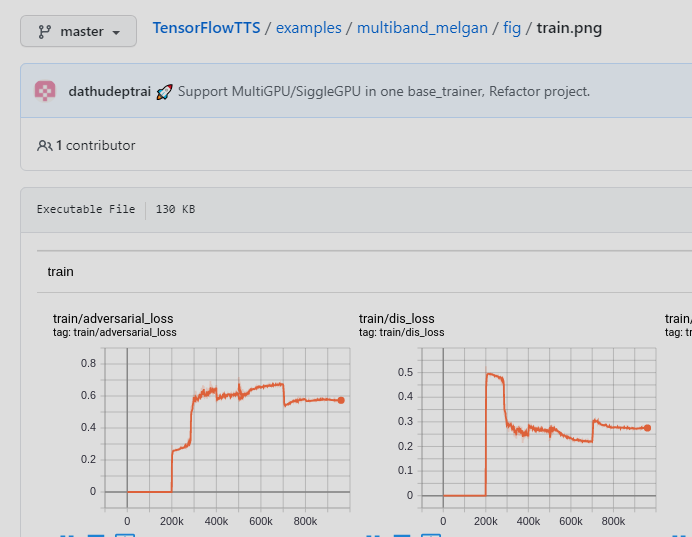
|
I also have this problem. My tensorboard:
and predictions are all same noisy sound. For example:
What could be the problem? I first trained generator and after resume. |
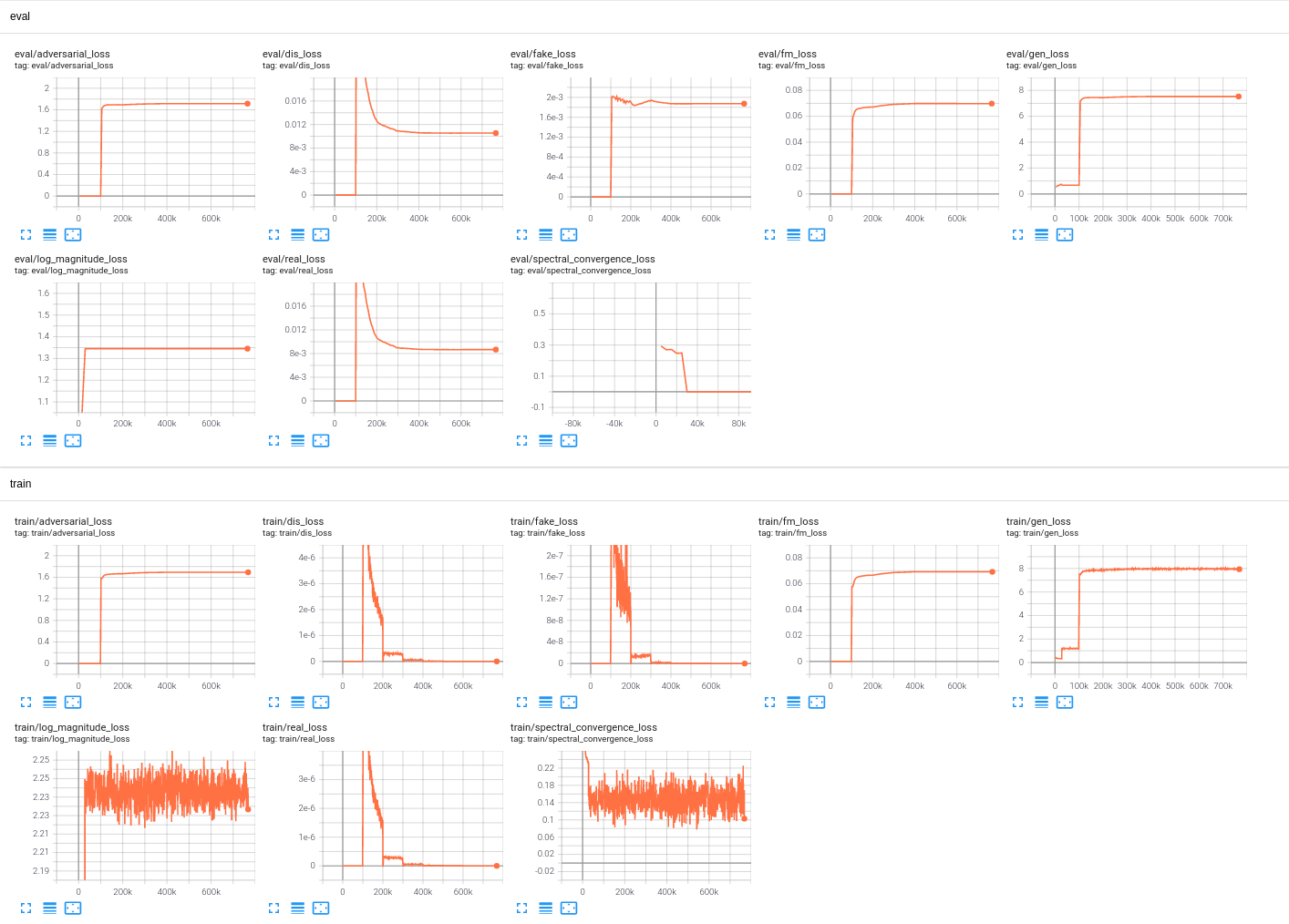
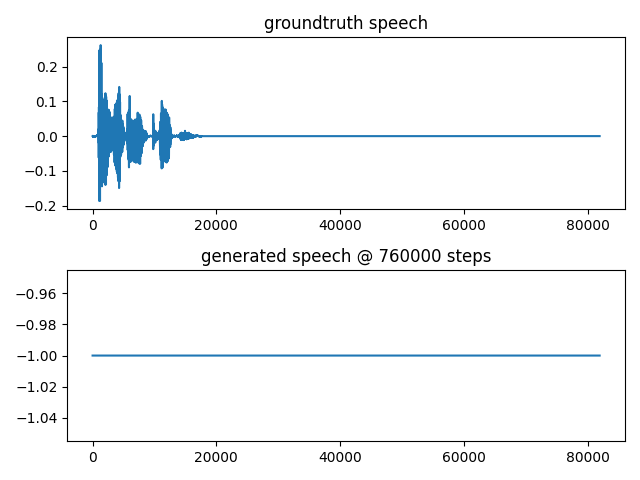
|
@EmreOzkose The TensorflowTTS implementation is not faithful to the original when it comes to the optimizer. The official implementation uses AdamW optimizer with ExponentialLR, while the one in this repo uses Adam with PiecewiseConstantDecay. Plus there is no generator pretraining in the original. |
|
I am checking out, thank you @ZDisket. |
I tried a training with the same setup and got different signals from a noise. Thank you 😃 |
|
@EmreOzkose Any updates? Did it do well? |
This PR is an implementation of the HiFi-GAN vocoder (https://arxiv.org/abs/2010.05646). The training process follows melgan_stft. The model logic follows by original HiFi-GAN PyTorch code (https://github.com/jik876/hifi-gan).